Quick Start
Each data generation order takes up to four input files in YAML format:
- Schema File: [required] It defines the structure of the data to be generated.
- Plan File: [required] It defines target data details, such as record number.
- Output Control File: [optional] It defines any modifications for data presentation.
- Data CSV File: [optional] It provides additional data to be used in the generation process.
For example, we can use this schema file and plan file to generate data, structured as illustrated below
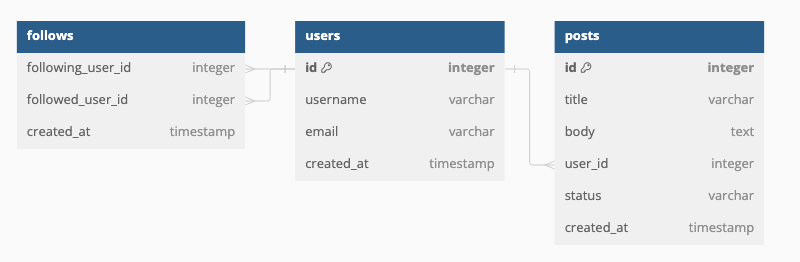 Based on the chosen output format type, each entity defined in the schema file will be generated as a separate file.
For example, if the output format is set to JSON, as illustrated, three files will be generated:
Based on the chosen output format type, each entity defined in the schema file will be generated as a separate file.
For example, if the output format is set to JSON, as illustrated, three files will be generated:
- users_0.json
- follows_1.json
- posts_2.json
The number trailing the entity name identifies the order in which the data should be applied to the target system, such as MySQL.
Schema File
The schema file is a YAML file that defines the structure of the data to be generated. It contains the following fields, both of which are required:
- name: The name of the schema, which serves as an ID to pair with the plan file.
- entities: A set of entity definitions. At least one entity is required. Entities with the same name are considered duplicates, and this will cause the data generation to fail.
An entity is the fundamental unit of data generation. The data for each entity will be stored in a distinct output file. An entity consists of a list of properties, each of which includes the following mandatory fields:
- name: This represents the name of the property.
- type: This denotes the data type of the property.
name: "quickstart"
entities:
- name: "users"
properties:
- name: "id"
type: "sequence"
Property Data Type
When defining a property under entity, the following data types are supported.
| Type | Description |
|---|---|
| sequence | An auto incremental integer number |
| text | A text value |
| number | A decimal number value, such as 100, -54 or 99.99 |
| date | A date value with day-level accuracy |
| datetime | A date time value with second level accuracy |
| time | A time value without date with second level accuracy |
Please refer to Property Data Type page for detailed usage.
Index, Constraints and Reference
To support complex data structures, users can define indices, constraints, and references in the schema file. This provides the capability to generate data with more intricate relationships.
- Index: This is used to establish the uniqueness of a property or a combination of properties.
- Constraints: This is used to set the constraints for a property, such as the minimum and maximum values.
- Reference: This is used to delineate the relationship between entities.
- Index Example
- Constraint Example
- Reference Example
properties:
- name: "id"
type: "sequence"
index:
id: 0
properties:
- name: "created_at"
type: "datetime"
constraints:
- type: "duration"
start:
year: 2023
month: 11
end:
year: 2023
month: 12
properties:
- name: "user_id"
type: "sequence"
reference:
entity: "users"
property: "id"
Plan File
The plan file, defining the data generation strategy, instructs the generator on using the targeted schema, including record count, additional constraints, and potential value distributions. It contains four primary elements:
- Name: [required] This is the name of the data plan and can be any text.
- Dialect: [optional] This refers to the targeted dialect. Supported values are "general", "mysql" and "salesforce". If not specified, the default value is "general".
- Schema: [required] This refers to the targeted schema. Its value must match the name defined in the schema file.
- Data: [required] This element comprises a list of entity data definitions, each detailing the instructions for generating the data for that particular entity. For each entry, a ‘count’ is required, which specifies the number of records to generate.
name: "quickstart"
dialect: "general"
schema: "quickstart"
data:
- entity: "users"
count: 10
Property Specification
For individual properties in entity data, users can optionally define extra specifications, such as constraints, distributions, and default values.
# For the ‘status’ property, assign the value ‘DELETED’ with a 10% probability,
# and use ‘ACTIVE’ as the default value.
properties:
- name: "status"
values:
- values:
- "DELETED"
weight: 0.1
defaultValue: "ACTIVE"
Output Control File
Though optional, the output control file enables auxiliary features to be applied to the generated data, particularly when Unicode or special characters are used in the user’s data model. The output control file provides the user with two capabilities:
- Name Replacement: This allows the user to modify the names of entities or properties in the output file.
- Property Hiding: This provides the user with the flexibility to hide certain properties in the output file.
- Name Replacement
- Property Hiding
# Replace the entity name ‘businessAccount’ with ‘account’
# Replace the property name ‘extId’ with ‘external_id’
name: "name_replacement"
entities:
- name: "businessAccount"
alias: "account"
properties:
- name: "extId"
alias: "external_id"
# Hide the property ‘accountRefId’ in the entity ‘contact’
name: "property_hiding"
entities:
- name: "contact"
properties:
- name: "accountRefId"
hide: true
Entity and property names in the schema and plan files should contain only alphanumeric characters, if possible. This can help avoid potential issues when generating data. Utilize the output control file to modify the names as needed.
Data CSV File
A csv file used to inject customer's data into the data generation. Please refer to Apply Your Own Data page for detailed instruction.